比如在无人驾驶场景中,我们有许多像素级分割的标注,但是并不知道这样的标注对无人驾驶的识别任务是最有效的,这一点难以证明。
第三是基于数据标注,必然导致常识的缺失,而人类对外部世界的认识很多依赖于常识。

我们在CVPR2019上提出用计算机图形学的技术生成虚拟场景,从虚拟场景中学习模型控制无感知的机械臂。
具体而言,我们只需要一个摄像头和一台计算机即可以控制没有装备其它感知设备的机械臂以完成复杂的搬运动作。因为这是从虚拟的环境中搜集的数据,因此标注的代价几乎为零。
此外,利用域迁移算法,所以几乎没有性能损失。如果融合强化学习,还能实现其它的多种任务,右边二维码是相关的代码和论文。

基于以上对数据、模型和知识方面的总结,我们提出了华为的视觉研究计划,希望能够助力每一位AI开发者。
我们的计划包括六个子计划,与数据相关的是数据冰山计划、数据魔方计划;与模型相关的是模型摸高计划、模型瘦身计划;与知识抽取相关的则是万物预视计划,也就是我们的通用预训练模型计划,此外还有虚实合一计划。
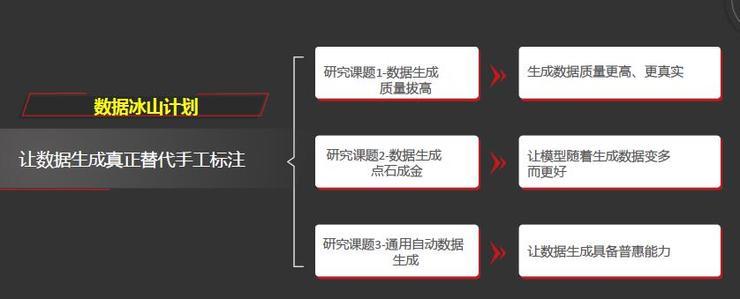
关于数据冰山计划,我们希望用数据生成方法真正代替手工标注。我们共有三个研究子课题,第一个子课题是希望数据的生成质量更高。
第二个研究课题是数据生成的点石成金计划,我们希望生成的数据能够自动挑选高质量的数据,让模型随着生成数据的变多而真正的变好。
第三个课题是通用自动数据生成,我们希望根据不同的任务自动生成它所需的数据,让数据生成具备普惠的能力。
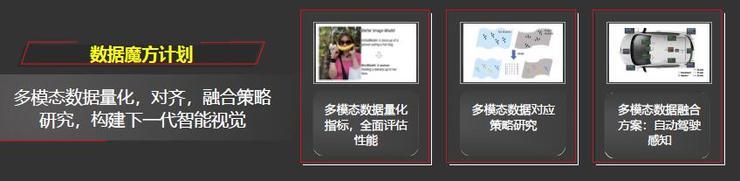
第二个数据计划是魔方计划,关注多模态数据量化、对齐、融合策略的研究,构建下一代的智能视觉。
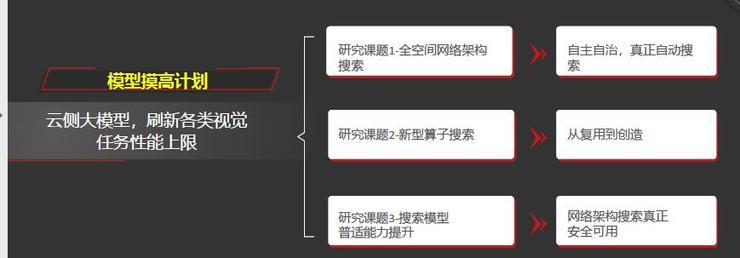
模型摸高计划考虑云侧大模型,刷新各类视觉任务性能上限。这包含了三个子课题:第一个是全空间网络架构搜索,希望不受算子、搜索网络的限制,真正实现自主自治,真正自动搜索。
第二个是新型算子搜索,希望设计与芯片相关的算子,让算子从复用到创造。
第三个是搜索模型的普适能力提升,之前提到搜索设计的模型与手工设计的模型相比普适性较差,我们希望将来的网络搜索能够真正的安全可用。
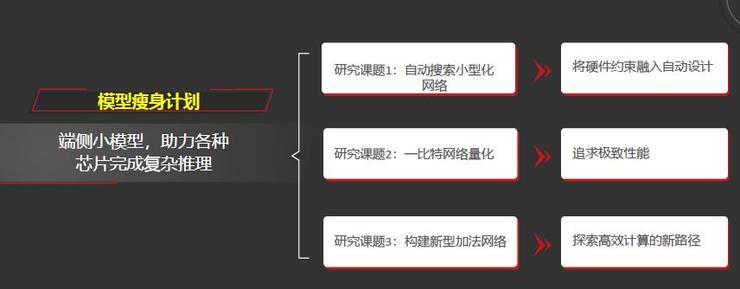
模型瘦身计划则针对端侧小模型,助力各种芯片完成复杂推理。其同样包含三个子课题:第一个小课题是自动搜索小型化,将硬件的约束融入自动设计,比如说功耗、时延的约束等。
第二个小课题研究低比特网络量化,尤其是一比特网络量化,追求极致的性能。
第三是构建新型的加法网络,探索高效计算的新途径。

最后两个计划跟知识相关,第一个是万物预视计划,主要目标是定义预训练任务以构建通用的视觉模型。

第二个是虚实合一计划,其主要目标是解决数据标注瓶颈的问题,希望在虚拟的场景下不通过数据标注,直接训练智能行为本身。
该领域早期的研究并不多,如何定义知识,如何构筑虚拟世界,如何模拟用户行为,如何在虚拟的场景中保证智能体的安全,比如说在虚拟的场景中做无人驾驶的训练,相信这是真正通向通用人工智能的一个有益的方向。
我们的视觉研究计划欢迎全球的AI研究者加入我们,这是基于昇腾AI计算平台,加速计算机视觉基础研究。
最后介绍一下我们的研究进展,以及华为云AI培养人才的理念。华为云AI希望打造一支世界一流的AI研究团队,主要从开放、创新、培养六个字践行,我们需要打造的是一个具有华为特色的人工智能军团。
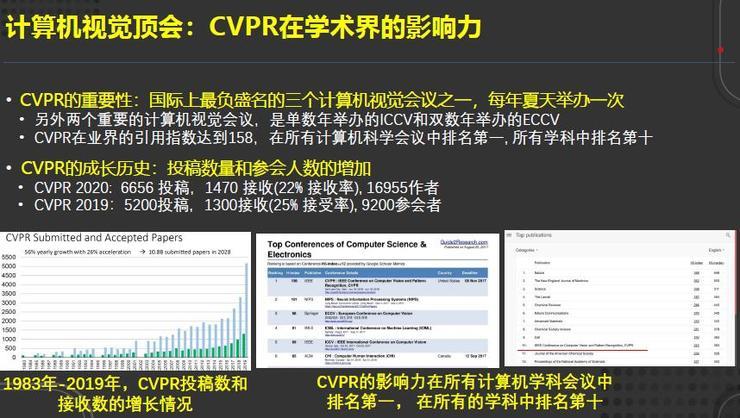
众所周知,在计算机视觉领域有三大顶会:CVPR、ECCV和ICCV。CVPR一年一次,ECCV和ICCV每两年一次。CVPR在本领域的会议中排名第一,在所有的计算机和非计算机学科中排名第10,具有广泛的影响力。
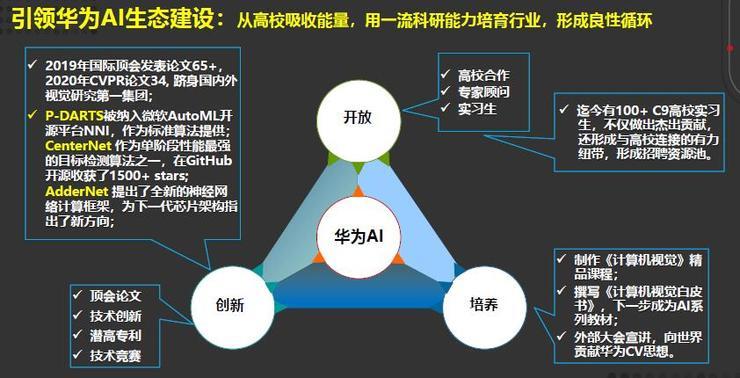
我们希望在各种顶会中取得更好的成绩,2019年我们的视觉团队在国际顶会发表论文60多篇,今年的CVPR有34篇论文,基础研究的论文发表已经跻身国际国内第一集团。
我们大量的工作也是通过我们的实习生和高校老师联合完成的,比如说P-DARTS,去年这项工作已经被纳入微软的开源平台,作为标准算法进行提供。
第二个是CenterNet,也是单阶段性能最强的目标检测算法之一,在GitHub开源收获了很高的评价。还有一个是AdderNet提出了全新的神经网络计算架构,为下一代芯片架构指出了新方向。
第二方面是开放,我们希望与顶级的高校老师合作,华为的视觉团队过去1-2年中有100多位C9高校和其它的高校的实习生,他们不仅做出了杰出的贡献,而且也形成了与高校之间有力的纽带。
第三是从培养的角度出发,视觉团队制作了计算机视觉精品课程,同时也撰写了计算机视觉白皮书,希望下一步成为AI系列教材,最后对内外部宣讲。
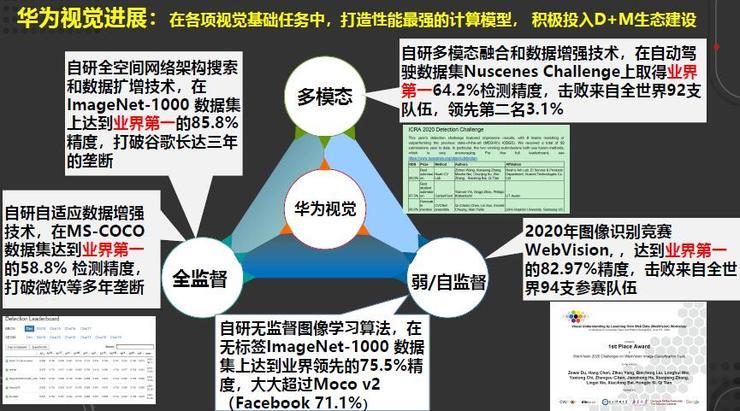
最后把我们半年来的视觉领域的进展与各位分享一下,我们的目标是希望在各项视觉基础任务中打造性能最强的计算模型,积极投入D+M生态建设。
在全监督学习方面,把全空间、网络架构搜索和数据扩增技术结合,在ImageNet达到85.8%的精度,打破谷歌三年的垄断。
另外,在自研的数据增强技术方面,在MS-COCO这样一个业界具有挑战的测试集,目前不管是单模型还是多模型,我们都达到业界第一,其中多模型达到58.8%的检测精度,也打破了微软多年的垄断。
在多模态学习方面,目前在自动驾驶数据集Nuscenes Challenge上取得业界第一的检测精度,击败来自全球92支队伍并大幅度领先第二名达3.1%。
最后,在弱监督方面,我们在2020年的图象识别竞赛WebVision达到业界第一的精度。在无监督方面,我们在无标签ImageNet-1000数据集上达到了业界领先的75.5%的精度,大大超过了Facebook保持的71.1%的精度。
未来希望我们的无监督学习能逼近甚至超越监督学习的极限。