
Page 23 - 中国仿真学会通讯2020第1期
P. 23
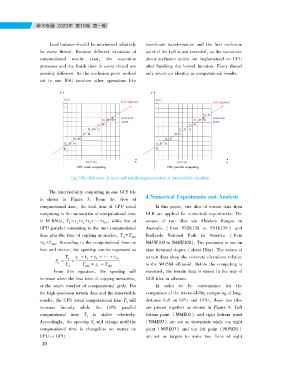
Load balance should be maximized relatively coordinate transformation and the first occlusion
for every thread. Because different situations of point of the LoS is just recorded, so the operations
computational results exist, the execution about occlusion points are implemented on CPU
processes and the finish time in every thread are after finishing the kernel function. Every thread
possibly different. As the occlusion point worked only return an identity as computational results.
out in one RSG involves other operations like
Fig.3.The difference of serial and parallel implementation of intervisibility algorithm.
The intervisibility computing in one GCS tile 4.Numerical Experiments and Analysis
is shown in Figure 3. From the view of In this paper, two tiles of terrain data from
DLR are applied for numerical experiments. The
computational time, the total time of CPU serial scopes of two tiles are Flinders Ranges in
Australia ( from S32E138 to S31E139 ) and
computing is the summation of computational time Badlands National Park in America ( from
N43W103 to N44W102) . The precision is one in
in 16 RSGs, Th = t1 +t2 +t3 +… +t16, while that of nine thousand degree ( about 10m) . The values of
GPU parallel computing is the unit computational terrain data show the concrete elevations relative
to the WGS84 ellipsoid. Before the computing is
time plus the time of copying memories, Td = Th2d executed, the terrain data is stored in the way of
+t1 +Td2h. According to the computational time on GCS tiles in advance.
host and device, the speedup can be expressed as
In order to be convenience for the
Sp = Th = t1 + t2 + t3 + … + t16 . comparison of the intervisibility computing of long⁃
Td Th2d + t1 + Td2h distance LoS on CPU and GPU, these two tiles
are pieced together as shown in Figure 4. Left
From this equation, the speedup will bottom point ( N04E01 ) and right bottom point
( N04E03) are set as viewpoints while top right
increase when the less time of copying memories, point ( N05E03 ) and top left point ( N05E01 )
are set as targets to make two lines of sight
or the much number of computational grids. For
the high⁃precision terrain data and the intervisible
results, the CPU serial computational time Th will
increase linearly while the GPU parallel
computational time Td is stable relatively.
Accordingly, the speedup Sp will enlarge until the
computational time is changeless no matter on
CPU or GPU.
20